欢迎各位读者,今天我们要聊聊一件新鲜事。没错,就是在一台24GB的消费级GPU上,如何对20B参数的大型语言模型(LLM)进行RLHF(人工反馈强化学习)的微调。这个工作得益于我们的新工具——trl和peft的完美结合。让我们一起来探索这个新颖的微调方法,以及它如何变得更加容易实现。
一、 LLMs & RLHF:AI领域的新星
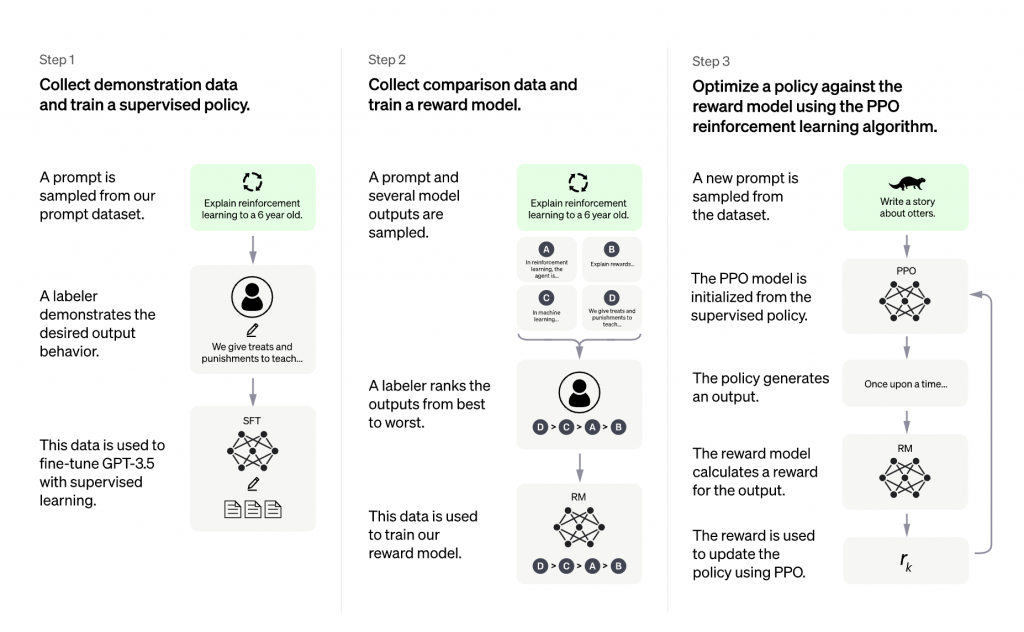
首先,让我们来了解一下大型语言模型(LLMs)和人工反馈强化学习(RLHF)。结合使用LLMs和RLHF,我们可以构建出像ChatGPT这样的强大AI系统。这个过程通常包括三个步骤:首先,我们在特定领域或语料库的指令和人类示例上微调预训练的LLM;然后,我们收集一个人工注释的数据集,训练一个奖励模型;最后,我们用奖励模型和这个数据集使用RL(比如PPO)进一步微调第一步中的LLM。
二、 什么是TRL?
trl库的目标是使RL步骤更容易和更灵活,任何人都可以在自定义的数据集和训练设置上使用RL微调他们的LM。你可以使用trl来运行最流行的深度RL算法,PPO,这可以在分布式方式或单一设备上实现!为了实现这一目标,我们利用了Hugging Face生态系统中的accelerate工具,以便任何用户都可以扩大实验规模。
三、 大规模训练的挑战
大规模训练可能会遇到挑战。首要挑战是将模型及其优化器状态装入可用的GPU设备。一个参数在GPU内存中所占的空间取决于其”精度”(或者更具体地说,dtype)。最常见的dtype包括float32(32位),float16和bfloat16(16位)。简单来说,要在GPU设备上加载一个模型,每十亿个参数在float32精度下需要4GB的内存,在float16下需要2GB,而在int8下需要1GB。
四、 8位矩阵乘法
8位矩阵乘法是一种高效的方法,首次在论文LLM.int8()中提出,旨在解决量化大规模模型时性能下降的问题。简单地说,如果你使用8位矩阵乘法,你可以将全精度模型的大小减少4倍(因此,对于半精度模型,可以减少2倍)。
五、 低秩适应和PEFT
在2021年的论文LoRA: Low-Rank Adaption of Large Language Models中,研究者们证明了可以通过冻结预训练的权重并创建低秩版本的注意力矩阵的查询和值层,对大型语言模型进行微调。这种技术使LLMs的微调只需要一小部分的内存需求。
六、 什么是PEFT?
参数高效微调(PEFT)是一个由Hugging Face创建的库,用于支持在LLMs上创建和微调适配器层。peft已经无缝地集成了Accelerate,可以利用DeepSpeed和Big Model Inference对大规模模型进行扩展。
七、 20B参数模型的低秩适配器微调
那么,现在让我们来具体谈谈如何在24GB的消费级GPU上对20B参数的LLM进行微调。我们通过使用TRL库,可以在个人的数据集和训练设置中用RL微调LM。TRL库使用Hugging Face生态系统的accelerate工具,使得任何用户都可以将实验规模扩大到有趣的范围。
而在大规模训练中,首要的挑战是如何将模型及其优化器状态装入可用的GPU设备。一种有效的解决方案是使用8位矩阵乘法,这种方法能够减少全精度模型的大小,从而使其适应硬件资源。
同时,我们引入了低秩适应和PEFT技术。低秩适应是一种可以通过冻结预训练的权重并创建低秩版本的注意力矩阵的查询和值层,对大型语言模型进行微调的技术。这种技术使LLMs的微调只需要一小部分的内存需求。而PEFT(参数高效微调)则是一个由Hugging Face创建的库,用于支持在LLMs上创建和微调适配器层。
这样,我们就可以在24GB的消费级GPU上进行20B参数模型的低秩适配器微调了。这个过程中,我们使用了trl和peft的集成,使得大型语言模型的微调变得更加容易实现,也更适应于硬件资源。
总的来说,我们现在有了更多的工具和方法来更有效地微调大型语言模型,这将使得AI系统,如ChatGPT,变得更加强大和实用。这是一次令人兴奋的进步,也预示着AI技术将带来更多的可能性。


