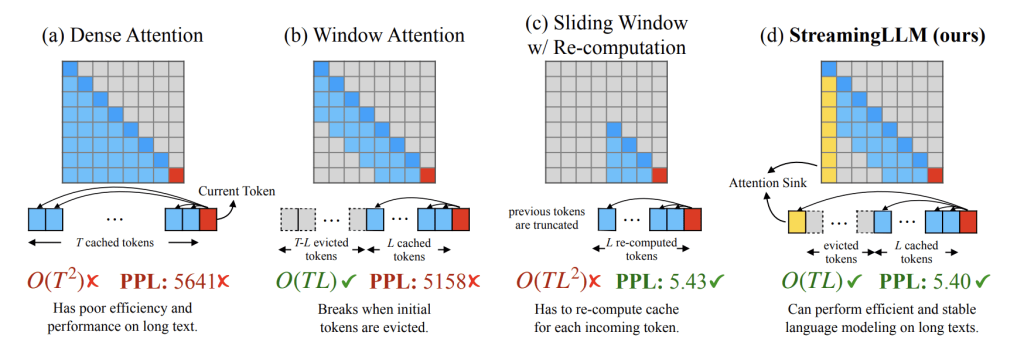
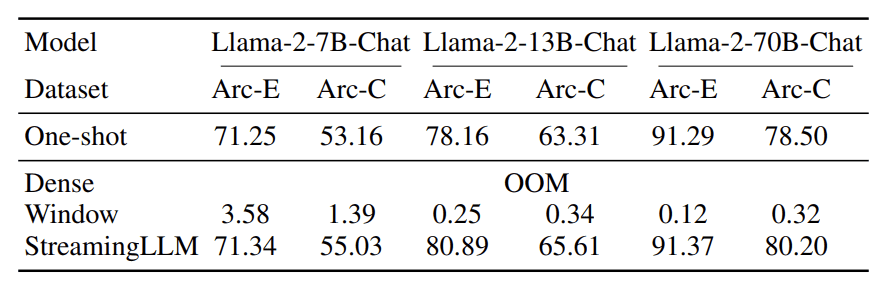
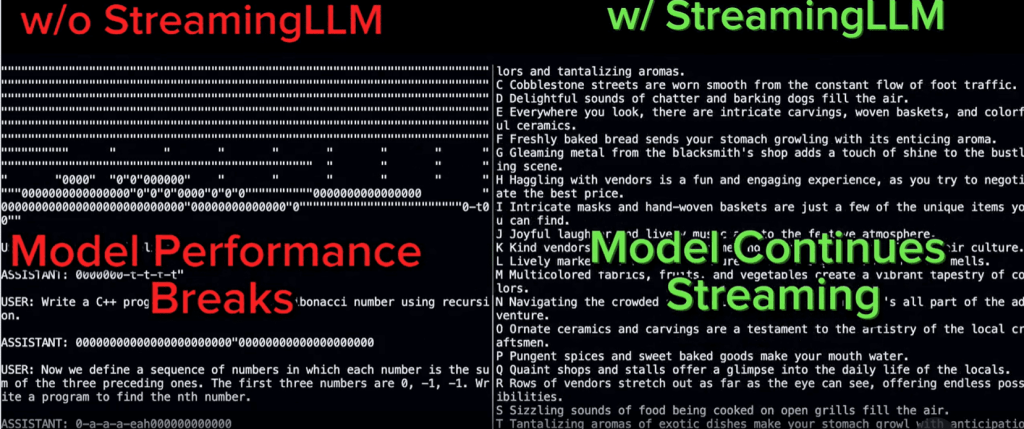
近年来,人工智能领域掀起了一股大模型热潮,而最近,长文本大模型的出现,更是将这场军备竞赛推向了新的高度。
Kimi Chat的横空出世,让业界意识到长文本大模型的巨大潜力。它能够处理高达200万字的上下文,这在以往是难以想象的。
百度文心一言也紧随其后,宣布下个月版本升级,将开放200万-500万字的长度。360智脑更是内测500万字,并计划将其整合到360AI浏览器中。阿里通义千问也开放了1000万字的处理能力。
海外方面,GPT4-turbo支持128K长度,Claude也支持200K。
这场长文本大模型的竞赛,究竟意味着什么?
长文本:大模型的「内存」
我们可以将大模型本身看作一个操作系统,它支持的文本上下文长度就如同操作系统的内存。内存越大,大模型一次性能够处理的信息就越多,也就能更好地理解和处理复杂的文本内容。
以往的大模型,由于内存有限,只能通过实时读写硬盘获取信息,类似于RAG(Retrieval-Augmented Generation)技术。这种方式需要先进行检索,提取相关信息,再进行处理和输出答案。
长文本大模型的出现,则意味着大模型拥有了更大的「内存」,能够直接处理更长的文本,无需依赖外部检索,从而提高效率和准确性。
长文本处理:两条路
目前,长文本处理主要分为两种方式:
- 有损压缩:对上下文进行压缩,以减少内存占用。
- 无损工程化硬怼:通过工程优化,尽可能保留原始信息。
Kimi号称其200K超长上下文是无损实现,但具体的技术方案尚未公开。
工程优化:突破瓶颈
如何实现无损超长上下文? 这成为了众多研究者关注的焦点。
知乎上的一些技术方案推测,主要集中在工程优化方面,例如:
- 优化内存管理:利用更先进的内存管理技术,例如KV Cache,来提高内存利用率。
- 优化Attention计算:例如Flash Attention和Ring Attention,利用GPU硬件特性或分布式计算,降低计算量和内存占用。
Dr.Wu在知乎上的回答非常精辟:「这个领域的研究十分割裂,容易出现NLP领域的paper一顿优化,kv cache一点没变,去优化那个attention的计算量,找错了瓶颈……」
以往的优化主要集中在算法层面,例如对Attention机制进行改进,以减少计算量。但这些方法往往会导致信息丢失,属于有损压缩。
Full Attention仍然是主流的计算方式,但其计算量巨大,尤其是对于长文本而言。
Full Attention:计算量之殇
Attention机制的计算公式如下:
![\[Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\]](https://www.zhichai.top/wp-content/ql-cache/quicklatex.com-71b1fd06c59028e5b4cfa37de15d3181_l3.svg "Rendered by QuickLaTeX.com")
其中,Q、K、V分别由文本输入向量乘以对应权重矩阵产生,维度为[seq_length, dim]。
当上下文长度很长时,seq_length会非常大,导致QK^T矩阵的维度也极其庞大,需要大量的内存空间来存储,并进行后续计算。
优化方案:Flash Attention & Ring Attention
Flash Attention利用GPU硬件特性,将计算尽可能地在SRAM这一层完成,降低GPU内存读取/写入。
Ring Attention则采用分布式计算,将Q、K、V矩阵分割到不同的硬件上,分别计算Attention,最后进行聚合,避免创建庞大的矩阵,从而降低内存占用和计算量。
长文本大模型:未来可期
长文本大模型的出现,为我们打开了新的视野。它不仅能够处理更长的文本,还能更好地理解和分析复杂的信息。
未来,随着技术的发展,长文本大模型将会在更多领域发挥重要作用,例如:
- 更精准的机器翻译:能够理解更长的上下文,翻译更加准确自然。
- 更强大的对话系统:能够进行更深入的对话,理解更复杂的语境。
- 更有效的文本摘要:能够提取更准确、更完整的文本信息。
长文本大模型的未来充满希望,让我们拭目以待!