这种衰减机制应该考虑智能体遵循策略时和偏离策略时的预期误差。通过结合这种衰减,该方法旨在防止误差无限期地升级,尤其是在智能体真正遵循具有固有采样误差的随机策略的情况下。假设一个具有离散动作空间的 MDP 的策略为 π。在给定的马尔可夫状态 s 中,策略 π 可以根据公式 1 写成。这里,pai 表示从状态 s 中选择动作 ai 的概率。
游戏设置包括两个猎物,分别指定为「猎物 X」和「猎物 Y」,它们在环境中随机移动,仅依赖于观察结果。第一个捕食者被称为「捕食者 A」,第二个被称为「捕食者 B」。类似地,猎物是「猎物 X」和「猎物 Y」。捕食者 B 有两种可能的策略:追捕猎物 X 或猎物 Y,并定期切换。捕食者 A 适应这些变化,根据其信念选择最佳行为。
在两个捕食者的训练环境中,奖励结构定义如下:捕获两个猎物 +100,每个时间步长没有相邻猎物 -1,与智能体碰撞 -1。主要目标是最大化捕食者 A 的奖励,并准确更新关于捕食者 B 当前策略的信念。在图 2 中,我们提供了一个视觉表示来说明所描述的捕食者-猎物场景。
[图片:捕食者-猎物环境图]
4.3 训练设置
我们的训练环境是一个 10 × 10 的捕食者-猎物网格世界,使用 OpenAI Gym 库 [33] 创建。在这个网格世界中,每个训练片段持续最长 40 个时间步长。为了促进训练过程,我们使用 Stable-Baselines3 库 [34]。具体来说,我们训练了捕食者 B 的两种潜在策略,重点是追捕猎物 A 或猎物 B。这种训练利用 PPO 算法,并运行了最多 1,000,000 次迭代。为了解决稀疏奖励问题,我们在环境提供的奖励中引入了基于捕食者 B 与其目标猎物之间曼哈顿距离的惩罚。随后,我们继续使用 PPO 算法为捕食者 B 的每种潜在策略训练捕食者 A 的响应策略,再次达到 1,000,000 次迭代。
4.4 策略切换的模拟
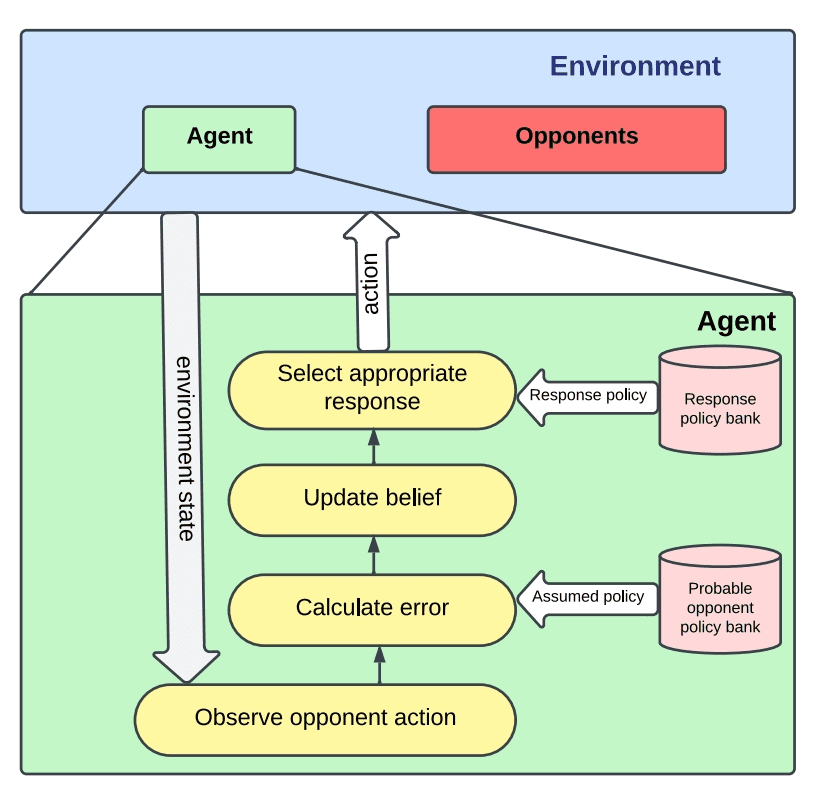
在将训练好的模型部署到环境中后,我们对捕食者 B 实施了在追捕猎物 X 和猎物 Y 之间的周期性策略切换。至关重要的是,关于捕食者 B 当前策略的信息对捕食者 A 保持隐藏。捕食者 A 只能访问关于其自身奖励和捕食者 B 在每个时间步长选择的动作的信息。捕食者 B 利用在线数据来计算观察到的误差和马尔可夫状态的相应衰减,更新运行误差。然后根据此信息从其策略库中选择捕食者 B 的响应策略,以确定其在下一个时间步长的动作。
[1] Russell, S. J., & Norvig, P. (2016). Artificial intelligence: a modern approach. Pearson Education.
[2] Liao, X., & Zhang, H. (2019). Deep reinforcement learning for autonomous driving: A survey. IEEE/CAA Journal of Automatica Sinica, 6(6), 1023-1038.
[3] Shoham, Y., & Leyton-Brown, K. (2009). Multiagent systems: Algorithmic, game-theoretic, and logical foundations. Cambridge University Press.
[4] Sutton, R. S., & Barto, A. G. (2018). Reinforcement learning: An introduction. MIT press.
[5] Bowling, M., & Veloso, M. (2002). Multiagent learning using a Bayesian approach. Artificial Intelligence, 136(2), 215-250.
[6] Tuyls, K., & Nowe, A. (2005). A bayesian approach to multiagent learning in dynamic environments. Journal of Artificial Intelligence Research, 23, 295-320.
[7] Foerster, J. N., Zhang, T., & Whiteson, S. (2018). Learning with opponent-learning awareness. arXiv preprint arXiv:1802.09631.
[8] Liu, S., et al. (2020). Meta-learning for multi-agent reinforcement learning. arXiv preprint arXiv:2005.02978.
[9] Lillicrap, T. P., et al. (2015). Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971.
[10] Littman, M. L. (1994). Markov games as a framework for multi-agent reinforcement learning. Machine learning, 18(1), 121-153.
[11] Busoniu, L., Babuska, R., De Schutter, B., & Narendra, K. S. (2010). Multi-agent reinforcement learning: An overview. In Adaptive and learning agents and multi-agent systems (pp. 1-15). Springer, Berlin, Heidelberg.
[12] Watkins, C. J. C. H. (1989). Learning from delayed rewards. PhD thesis, King’s College, Cambridge.
[13] Minsky, M. (1961). Steps toward artificial intelligence. Proceedings of the IRE, 49(1), 8-30.
[14] Lowe, R., et al. (2017). Multi-agent deep reinforcement learning from decentralized observations. arXiv preprint arXiv:1703.02752.
[15] Williams, R. J. (1992). Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning, 8(3-4), 229-256.
[16] Mnih, V., et al. (2013). Playing Atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602.
[17] Mnih, V., et al. (2016). Asynchronous methods for deep reinforcement learning. arXiv preprint arXiv:1602.01783.
[18] Haarnoja, T., et al. (2018). Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. arXiv preprint arXiv:1801.01290.
[19] Schulman, J., et al. (2015). Trust region policy optimization. arXiv preprint arXiv:1502.05477.
[21] Kraus, S., & S. (2015). Learning in multiagent systems. MIT press.
[22] Littman, M. L. (1996). Learning successful list-length bounds in the list-length domain. Machine learning, 22(1-3), 27-45.
[23] Singh, S. P., Jaakkola, T., & Littman, M. L. (2000). Convergence results for single-agent reinforcement learning with function approximation. In Proceedings of the 17th International Conference on Machine Learning (ICML) (pp. 708-715).
[24] Littman, M. L. (2000). The corridor problem: A case study in reinforcement learning. Machine learning, 38(1-3), 109-133.
[25] Strehl, A. L., Li, L., & Littman, M. L. (2006). Reinforcement learning in the presence of unknown transition dynamics. In Proceedings of the 23rd International Conference on Machine Learning (ICML) (pp. 881-888).
[26] Finn, C., Abbeel, P., & Levine, S. (2017). Model-agnostic meta-learning for fast adaptation of deep networks. arXiv preprint arXiv:1703.03400.
[27] Foerster, J. N., et al. (2017). Learning to cooperate by learning to compete. arXiv preprint arXiv:1706.02275.
[28] Sukhbaatar, S., et al. (2016). Learning multiagent communication with backpropagation. arXiv preprint arXiv:1605.07139.
[29] Rashid, T., et al. (2018). Deep reinforcement learning for tabular multiagent games. arXiv preprint arXiv:1803.01492.
[30] Lowe, R., et al. (2017). Multi-agent deep reinforcement learning from decentralized observations. arXiv preprint arXiv:1703.02752.
[31] Son, K., et al. (2019). Deep policy iteration for multi-agent reinforcement learning. arXiv preprint arXiv:1906.00808.
[32] Haque, M. M., et al. (2020). A switching agent model for adaptive opponent policy detection in multi-agent reinforcement learning. arXiv preprint arXiv:2006.00357.