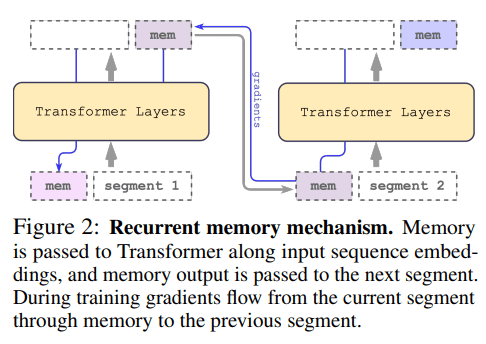
Scaling Transformer to 1M tokens and beyond with RMT 这份技术报告展示了循环记忆的应用,以扩展 BERT 的上下文长度,这是自然语言处理中最有效的基于 Transformer 的模型之一。通过利用循环记忆 Transformer 架构,我们成功地将模型的有效上下文长度增加到前所未有的 200 万个标记,同时保持高记忆检索精度。我们的方法允许存储和处理局部和全局信息,并通过使用递归实现输入序列段之间的信息流。我们的实验证明了我们方法的有效性,这具有巨大的潜力来增强自然语言理解和生成任务的长期依赖处理,并为记忆密集型应用程序启用大规模上下文处理。