引言 大型语言模型究竟能学到什么?这是一…
大型语言模型(LLM)在自然语言处理领域取…
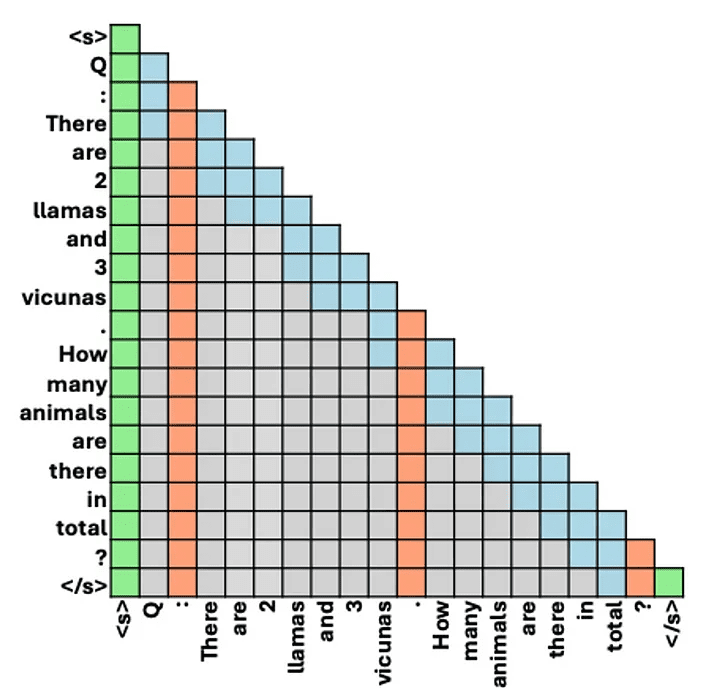
近年来,变形金刚(Transformers)凭借其…
循环神经网络(RNN)长期以来一直是建模时…
循环神经网络(RNNs)长期以来一直是处理…
近年来,大型语言模型(LLM)在各个领域都…