《
@misc{jin2024llm,
title={LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning},
author={Hongye Jin and Xiaotian Han and Jingfeng Yang and Zhimeng Jiang and Zirui Liu and Chia-Yuan Chang and Huiyuan Chen and Xia Hu},
year={2024},
eprint={2401.01325},
archivePrefix={arXiv},
primaryClass={cs.CL}
}》这篇论文介绍了一种名为 Self-Extend 的新方法,该方法可以在不进行微调的情况下,有效地扩展大型语言模型 (LLM) 的上下文窗口。
1. 引言
大型语言模型 (LLM) 在各种任务中都取得了显著的成果,但其应用受限于训练序列的长度。为了解决这个问题,本文提出了一种名为 Self-Extend 的方法,该方法可以有效地扩展 LLM 的上下文窗口,而无需进行任何微调。
2. Self-Extend 方法概述
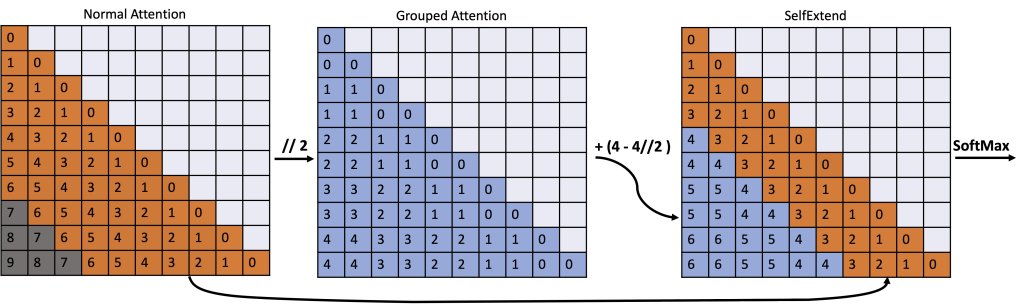
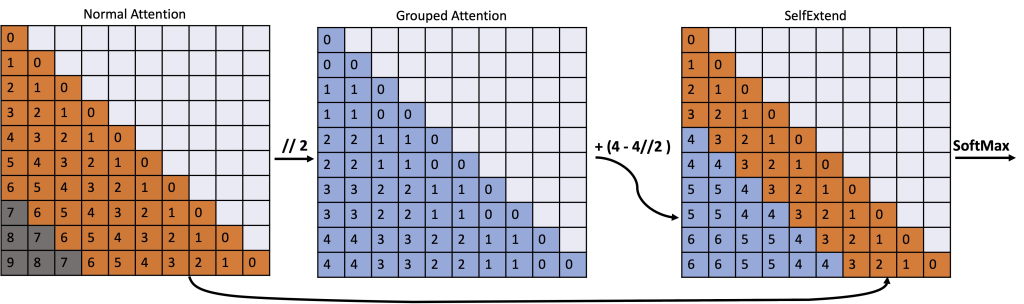
Self-Extend 方法的核心思想是构建双层注意力信息:组级别和邻居级别。这两种级别的注意力信息都是通过原始模型的自注意力机制计算得到的,这意味着该方法不需要任何额外的训练。
2.1 双层注意力机制
- 组级别注意力: 将输入序列划分为多个组,每个组包含多个词语。组级别注意力机制计算每个组与其他所有组之间的注意力权重。
- 邻居级别注意力: 在每个组内,邻居级别注意力机制计算每个词语与其邻居词语之间的注意力权重。
通过结合组级别和邻居级别注意力信息,Self-Extend 方法可以有效地扩展 LLM 的上下文窗口,使其能够处理更长的输入序列。
如下图所示:
3. Self-Extend 的使用
3.1 环境配置
目前,Self-Extend 方法已在 Llama 模型上进行了测试,所需的 Python 包如下:
transformers==4.38.2
flash_attn==2.5.6 推荐使用以下 Docker 镜像: hoytjin/selfextend_docker:v0.1
3.2 运行 Self-Extend
import SelfExtend
# 加载模型,例如:loaded_model = AutoModelForCausalLM.from_pretrained(model_path)
# 设置组大小和邻居窗口大小
SelfExtend.apply(loaded_model, group_size, window_size, enable_flash_attention=False)
# 进行推理,例如:loaded_model.generate(...)默认情况下,enable_flash_attention=False。如果模型加载时启用了 FlashAttention,则可以设置 enable_flash_attention=True。
以下代码示例展示了如何使用 Self-Extend 方法进行密钥检索:
python example.py4. 如何选择组大小和邻居窗口大小
选择合适的组大小和邻居窗口大小对于 Self-Extend 方法的性能至关重要。以下是一些经验法则:
- 以 Llama-2 为基础模型,2~64 是合理的组大小;512~1536 是可行的邻居窗口大小。但在许多情况下,较大的组大小和较小的邻居窗口大小也是不错的选择。
- 选择组大小和邻居窗口大小的一般原则是:确保输入序列长度在最大扩展窗口大小之内(对于 Llama-2,最大扩展窗口大小为 (4096 – 邻居窗口大小) * 组大小 + 邻居窗口大小)。
- 作者并没有仔细选择组大小。对于相同的序列,较小的组应该更好。但在一些实验中,作者发现情况并非总是如此:
有时,较大的组大小可能更有益。这可能是因为较大的位置没有得到很好的训练。较大的组大小可以利用在预训练中接受过更多训练的较小位置来促进扩展。然而,较小的组大小往往具有更好的精度。因此,这是一个权衡。更多细节请参考消融研究部分。
例如:
如果问答任务的输入长度为 15,800,邻居窗口大小设置为 1,024,则组大小可以设置为 5。这是因为 5 * (4,096 – 1,024) + 1,024 等于 16,384,大于 15,800。然而,将组大小设置为 6,甚至更大,例如 8 或 16,可能会提高模型的性能。当组大小为 5 时,Self-Extend 使用位置 1,025 到 3,979 来扩展上下文窗口。如果组大小设置为 8,Self-Extend 使用位置 1,025 到 2,871 进行扩展。虽然组大小为 8 的精度低于组大小为 5,但在预训练期间,组大小为 5 时使用的位置 2,872 到 3,979 的训练程度较低,这可能会影响扩展的有效性。
- 也许,对于长度为 L 的序列,可以先尝试最小的组大小 [计算公式为:G * (L- w_n) + w_n],然后测试更大的组大小是否更好。
Self-Extend 在“大海捞针”任务上的表现
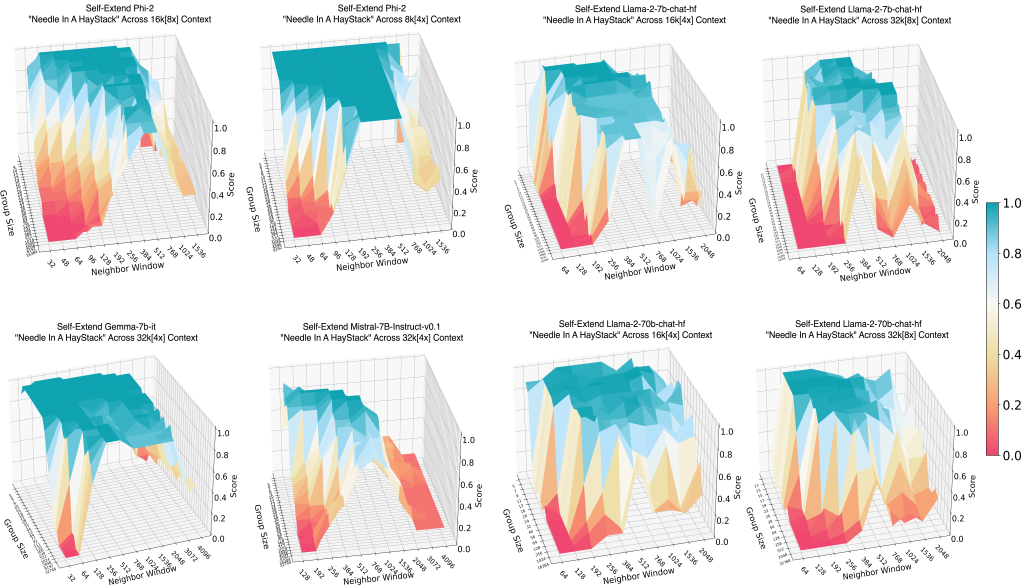
经验法则
将预训练上下文窗口表示为  ,目标扩展长度表示为
,目标扩展长度表示为  ,邻居窗口表示为
,邻居窗口表示为  ,组大小表示为
,组大小表示为  ,选择超参数的经验法则是确保以下不等式成立:
,选择超参数的经验法则是确保以下不等式成立:  这是经验性的,作者认为这是因为:较大的相对位置没有得到很好的训练。根据经验,只有一部分(
这是经验性的,作者认为这是因为:较大的相对位置没有得到很好的训练。根据经验,只有一部分( )的位置得到了很好的训练,Self-Extend 应该只利用这些训练有素的相对位置进行扩展。这一发现解释了:
)的位置得到了很好的训练,Self-Extend 应该只利用这些训练有素的相对位置进行扩展。这一发现解释了:
- 过小的组大小会降低性能,因为它们提供了精确的位置信息,但需要 Self-Extend 利用训练程度较低的相对位置进行扩展。
- 过大的邻居窗口大小也会降低性能,因为它们提供了更多的邻居信息,但需要利用训练程度较低的相对位置进行扩展。
实验结果表明,Self-Extend 对超参数的选择并不十分敏感。预先定义的、启发式的组大小和邻居窗口大小值通常足以获得令人满意的性能。
[TLDR]
Self-Extend 对超参数的选择并不十分敏感。可以使用一个代表性任务来找到合适的超参数。或者直接遵循作者的经验不等式:
5. 总结
Self-Extend 是一种简单而有效的方法,可以在不进行微调的情况下扩展 LLM 的上下文窗口。该方法易于实现,并且可以应用于各种 LLM 模型。实验结果表明,Self-Extend 方法可以显著提高 LLM 在长文本任务上的性能。
参考文献
@misc{jin2024llm,
title={LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning},
author={Hongye Jin and Xiaotian Han and Jingfeng Yang and Zhimeng Jiang and Zirui Liu and Chia-Yuan Chang and Huiyuan Chen and Xia Hu},
year={2024},
eprint={2401.01325},
archivePrefix={arXiv},
primaryClass={cs.CL}
}