引言
自2017年被提出以来,Transformer已成为AI大模型的主流架构,在语言建模领域长期占据主导地位。然而,随着模型规模不断扩大、需要处理的序列越来越长,Transformer的局限性也日益凸显。其中一个明显的缺陷是:Transformer模型中自注意力机制的计算量会随着上下文长度的增加呈平方级增长。
几个月前,一种名为Mamba的新型架构的出现打破了这一局面。Mamba能够随上下文长度的增加实现线性扩展,在中小型规模上已经实现了与Transformers匹敌甚至超越的性能。
仅仅六个月后,Mamba的原作者团队再接再厉,推出了更强大的Mamba 2。本文将详细介绍Mamba 2的核心创新点及其相比Transformer的优势。
Mamba 2的核心创新
1. SSD框架:连接SSM和Transformer
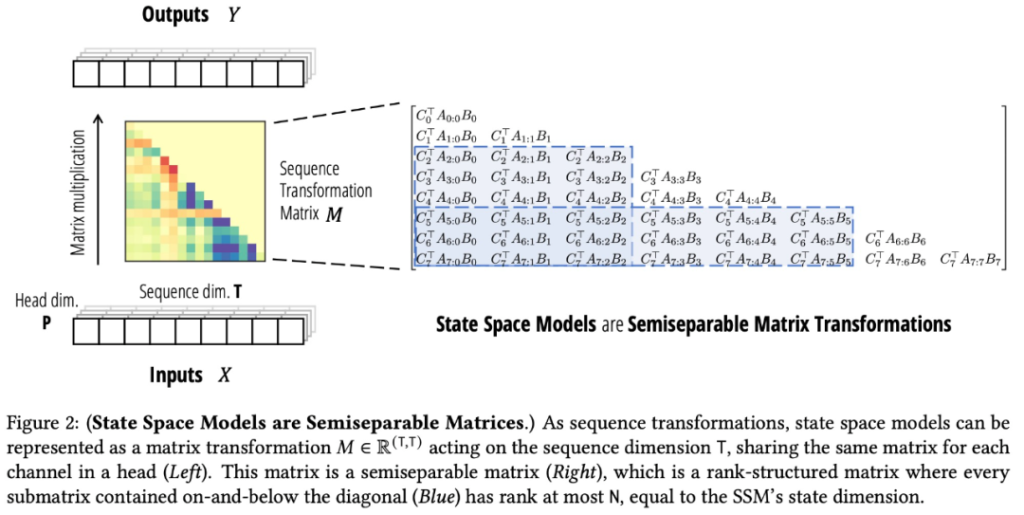
Mamba 2的核心贡献是提出了SSD(State Space Duality)框架。这一框架揭示了状态空间模型(SSM)与一类称为半可分矩阵的结构化矩阵族之间的等价性。通过SSD框架,研究者建立了SSM和Transformer之间的理论联系,为理解和改进序列模型开辟了新的方向。
SSD框架的主要内容包括:
- 展示了状态空间模型与半可分矩阵之间的等价性
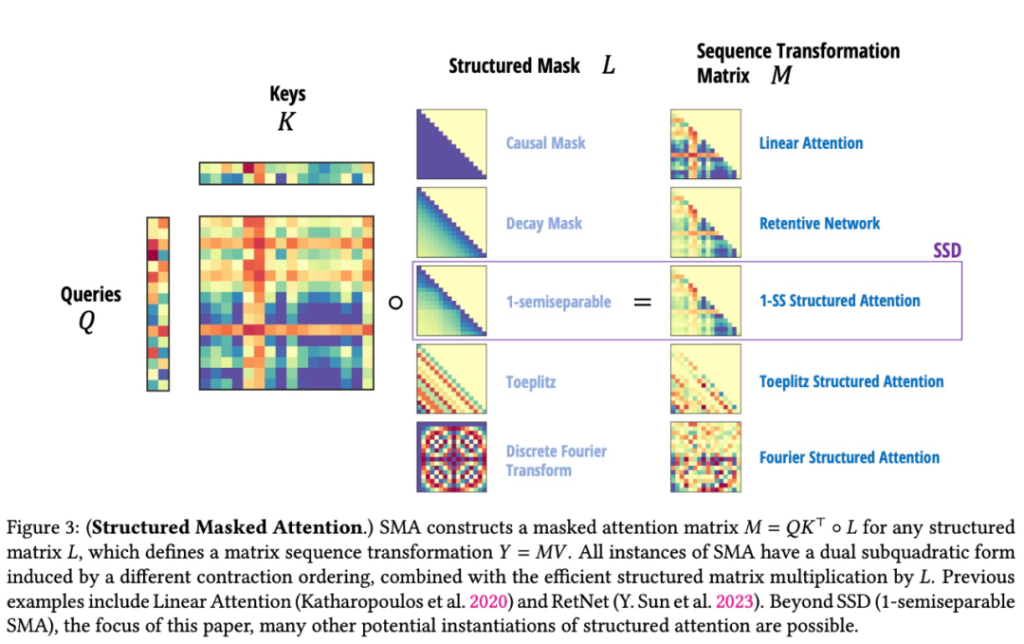
- 改进了线性注意力理论,推广出新的结构化掩码注意力(SMA)族
- 证明了SSM和SMA有很大的交集,它们是对偶的
- 证明了任何具有快速循环形式的核注意方法都是SSM
2. 高效的SSD算法
基于SSD框架,研究者提出了一种新的高效算法来计算SSM。这种基于半可分离矩阵块分解的SSD算法,利用了SSM的线性递推和二次对偶形式,在各个效率维度上都取得了最优权衡。
与Mamba的实现相比,SSD算法的速度提高了2到8倍。同时,它还允许使用更大的循环状态大小(是Mamba的8倍甚至更高),而几乎不影响速度。在长序列处理上,SSD算法的优势更加明显 – 在16K长度的序列上,它比优化过的softmax注意力实现(FlashAttention-2)快6倍。
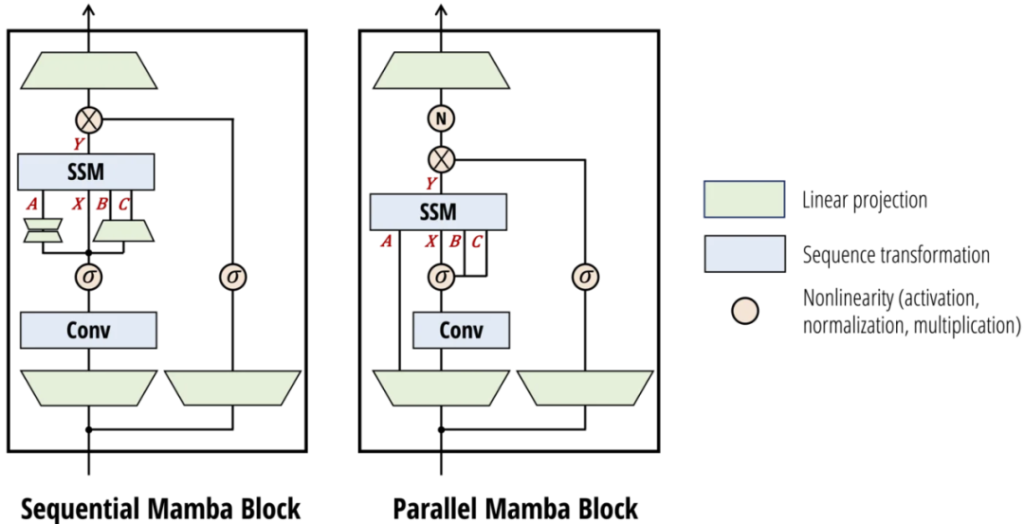
3. 改进的架构设计
Mamba 2在网络架构上也做了一些改进:
- 从顺序生成变为并行生成SSM参数
- 引入分组值注意力(GVA)头结构
- 更适合张量并行等扩展方法
这些改进使得Mamba 2在保持模型表达能力的同时,显著提高了训练效率,特别是能够更好地利用现代加速器上的矩阵乘法单元。
Mamba 2的性能优势
1. 语言建模任务
研究者在Pile数据集上训练了一系列Mamba 2模型,结果显示Mamba 2在标准下游评估中匹配或超过了Mamba和开源的Transformers。
例如,在Pile上训练了3000亿token的2.7B参数Mamba 2模型,其性能超过了:
- 在同一数据集上训练的2.8B参数Mamba模型
- 2.8B参数的Pythia模型
- 6.9B参数的Pythia模型
这一结果表明,Mamba 2不仅能够与同等规模的Transformer模型相匹敌,甚至能够在更小的参数量下超越更大的Transformer模型。
2. 复杂关联回忆任务
研究团队在MQAR(multi-query associative recall)任务上对比了Mamba 2和Mamba 1的性能。MQAR是一种比文献中通常报告的版本更难的任务,要求模型具有更强的长程依赖建模能力。
实验结果显示,Mamba 2明显优于Mamba 1。研究者认为,性能提升的一个重要原因是Mamba 2使用了更大的状态大小(比Mamba 1大约16倍)。这说明Mamba 2在处理需要更大状态容量的任务上有显著优势。
3. 训练效率
Mamba 2在训练效率方面也有明显提升。研究者在与Mamba相同的设置中研究了Mamba 2的Chinchilla扩展法则,发现它在困惑度和实际运行时间方面均优于Mamba和Transformer++。
这意味着,在相同的计算资源下,Mamba 2能够更快地收敛到更好的性能,从而大幅提高模型训练的成本效益比。
Mamba 2的理论意义
Mamba 2不仅在实际性能上有显著提升,其背后的理论创新也具有重要意义:
- SSD框架提供了状态空间模型、注意力机制和结构化矩阵之间丰富的联系,为未来的序列模型研究开辟了新的方向。
- 通过建立SSM和Transformer之间的理论联系,Mamba 2为两种不同范式的模型架构搭建了桥梁,有助于研究者更好地理解和改进这两类模型。
- SSD算法的提出为高效计算SSM提供了新的思路,这一算法不仅适用于Mamba系列模型,也可能被应用到其他基于SSM的模型中。
结论
Mamba 2的出现为序列建模领域带来了新的可能性。它不仅在性能上挑战了长期占据主导地位的Transformer,更重要的是提供了一种新的思路来构建和理解序列模型。
虽然目前Mamba 2主要在中小规模模型上展现出优势,但其线性扩展的特性使它在处理超长序列时具有巨大潜力。随着进一步的研究和优化,Mamba系列模型很可能在更多任务和更大规模上挑战Transformer的地位。
然而,需要注意的是,Transformer模型经过多年发展已经形成了成熟的生态系统。Mamba要真正取代Transformer还需要时间和更多的实践验证。未来,我们可能会看到Transformer和Mamba各自在不同场景下发挥优势,或者两者结合形成新的混合架构。
无论如何,Mamba 2的出现无疑为AI领域注入了新的活力,推动了序列模型的进一步发展。它的成功再次证明,在人工智能领域,创新永不止步。
参考文献
- Gu, A., Dao, T. et al. (2024). Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. arXiv preprint.
- Zhou, W. et al. (2024). 再战Transformer!原作者带队的Mamba 2来了,新架构训练效率大幅提升. 腾讯云开发者社区.
- Vaswani, A. et al. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems.
- Gu, A., Dao, T. et al. (2023). Mamba: Linear-Time Sequence Modeling with Selective State Spaces. arXiv preprint.