《H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models》
当我们谈论人工智能尤其是语言模型时,你可能会想象一个强大的机器,它能够写作、聊天,甚至创作诗歌。但这背后的真相是,这些模型的运行需要巨大的计算资源,尤其是在处理长篇内容时。然而,科技的步伐从未停歇,一个名为H2O的新工具出现了,它让大型语言模型的应用变得更加高效和便捷。
迈向更高效的未来:H2O的诞生 🌟
有鉴于大型语言模型(LLMs)在部署时所需成本的不断攀升,特别是在长内容生成如对话系统与故事创作领域,研究者们提出了一种全新的解决方案。这个解决方案的核心在于对所谓的KV缓存的智能管理。KV缓存是一种在GPU内存中存储临时状态信息的机制,其大小与序列长度和批处理大小成线性关系。但H2O通过一种创新的方法大幅度降低了KV缓存的内存占用。
重点词(Heavy Hitters):H2O的核心思想 💡
H2O背后的一个关键发现是,在计算注意力得分时,只有少数的词语(我们称之为重点词,H2)占据了大部分的价值。研究表明,这些重点词的出现与文本中词语的频繁共现强烈相关,一旦去除这些重点词,模型的性能会显著下降。
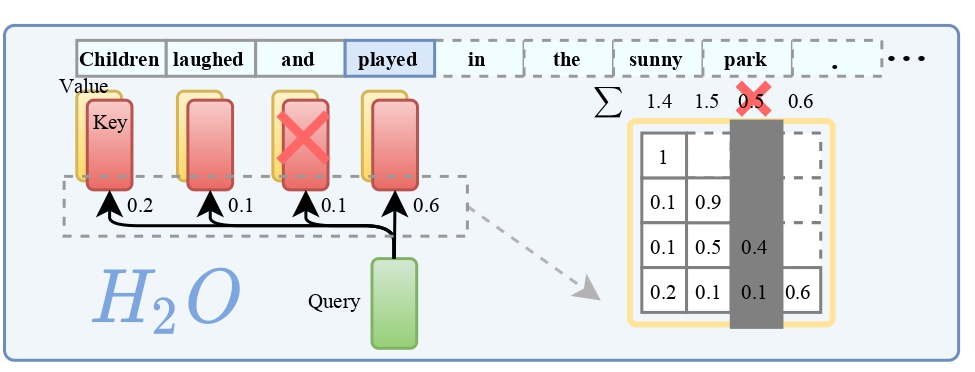
基于这一发现,H2O采用了一种KV缓存淘汰策略,它动态地保留了最近的词和重点词之间的平衡。通过将KV缓存淘汰形式化为一个动态子模块问题,研究者们还为这一算法提供了理论上的保证。
高效实践:H2O的验证与实现 🛠
H2O不仅仅停留在理论上,它的有效性已经在多个任务和不同大小的模型(如OPT和GPT-NeoX)上得到了验证。使用H2O并将重点词的比例设为20%,在OPT-6.7B和OPT-30B上,相比于目前领先的三种推理系统——DeepSpeed Zero-Inference、Hugging Face Accelerate和FlexGen,吞吐量提高了多达29倍。
开源共享:H2O与社区的互动 🌐
H2O项目已在GitHub上开源,任何人都可以访问其代码仓库。项目提供了两种代码实现:
h2o_flexgen:基于FlexGen,用于提升大型语言模型生成的吞吐量。h2o_hf:基于Hugging Face,测试不同基准上的性能,同时提供了模拟代码(掩蔽注意力矩阵)和真实KV淘汰实现。
结语:技术的进步,让创新触手可及 ✨
H2O的出现,不仅是技术的一大步,更是人工智能领域里一个值得纪念的里程碑。它使得原本资源密集的大型语言模型变得更加亲民,让更多的开发者和用户能够享受到AI的好处。