
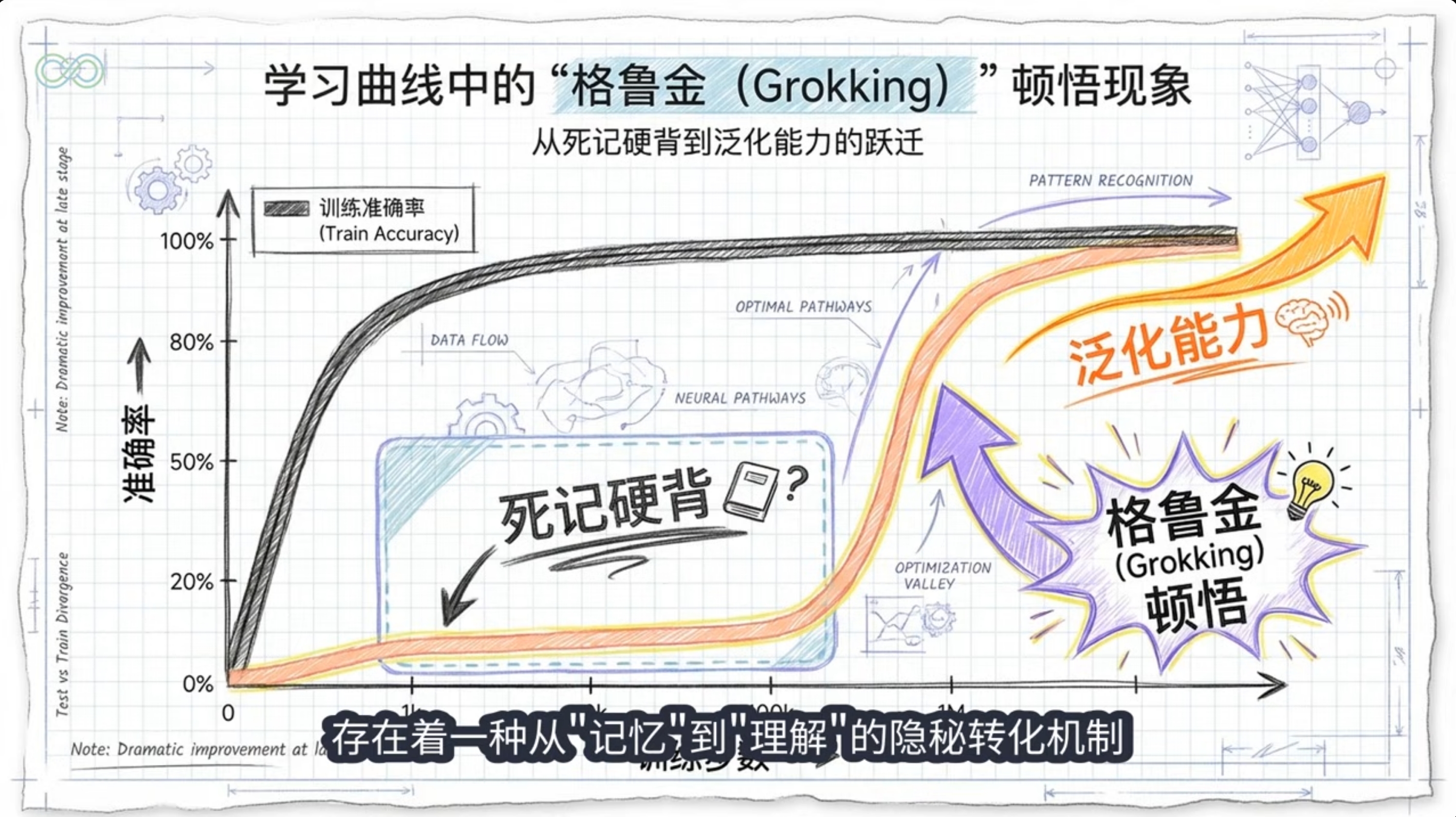
!屏幕截图_22-12-2025_13505_www.youtube.com.jpeg — Grokking是神经网络训练中一种延迟泛化相变现象:在过拟合后,继续训练导致模型从记忆转向结构化理解(如算法电路或三角表示)。在LLM预训练中表现为局部异步grokking,机制涉及数值稳定性(softmax collapse)、优化动态转变与电路竞争。2024-2025研究深化了数值与相变视角,证实其在真实LLM中的存在。
{kind=link}
行动建议
– 研究者:监控预训练中数据子集损失与内部路径演化,作为廉价泛化指标。 – 实践者:适度延长训练并加强正则化,可能诱导更好泛化;关注数值精度优化(如Muon优化器)。
!屏幕截图_22-12-2025_14234_www.youtube.com.jpeg
归纳偏置是Grokking机制的核心驱动力:训练早期隐式/显式偏置倾向记忆化解(快速拟合),晚期偏置(如权重衰减驱动的最小范数、电路效率,或优化器Slingshot)转向简洁泛化解,导致从过拟合到延迟泛化的尖锐相变。2023-2025研究证实阶段二分偏置可严谨证明Grokking,并在LLM中表现为局部异步现象。
行动建议
– 研究者:调整初始化规模、权重衰减与优化器,监控电路/秩演化,作为Grokking指标。
– 实践者:使用Adam等自适应优化器并延长训练,结合合适正则化诱导更好泛化。
风险提示
偏置不总是促进泛化,可能在复杂任务导致误导;理论多限于小模型,LLM应用需谨慎。