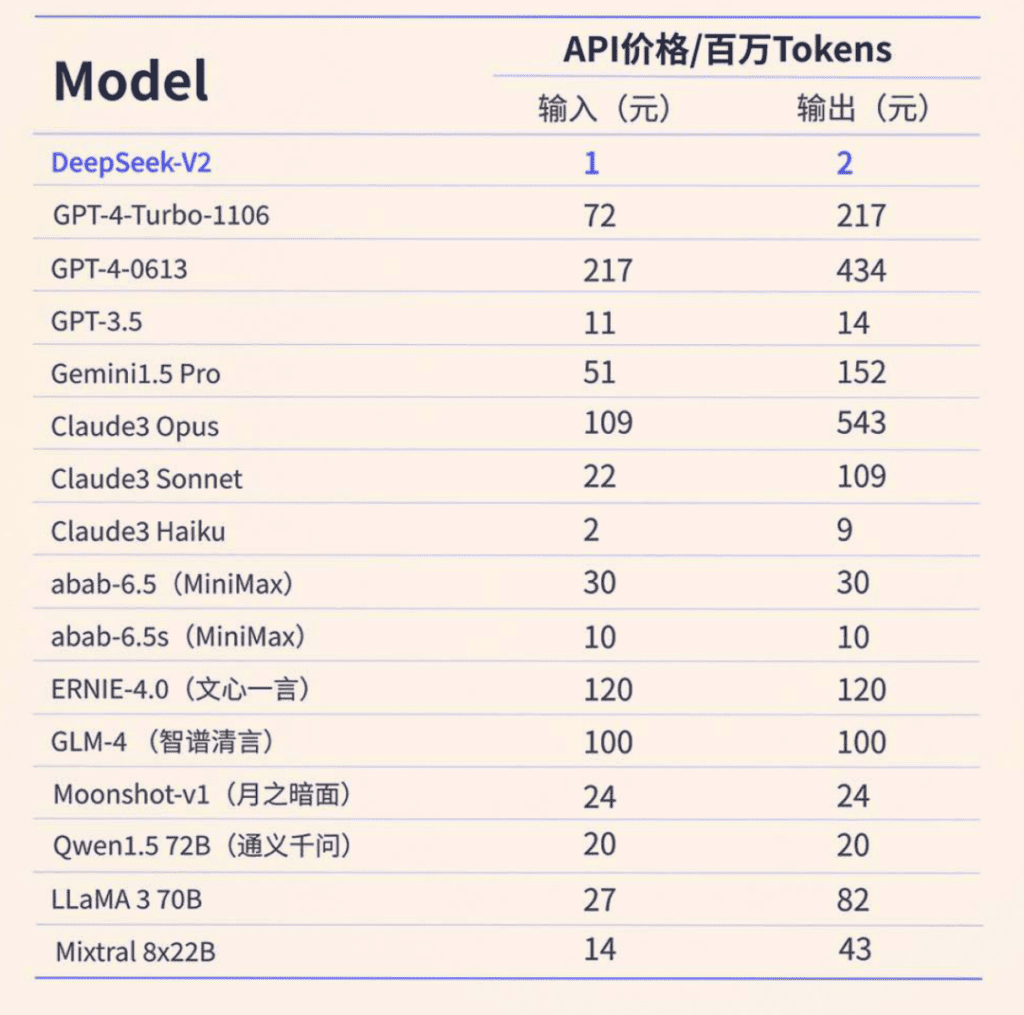
导语:在自然语言处理(NLP)任务中,反事实生成在模型开发和评估中扮演重要角色。然而,传统的反事实生成方法需要大量训练数据和模型微调,不太实用。因此,本研究提出了一个新的问题:如何在零样本情况下生成高质量的反事实示例?为此,我们提出了一种创新的方法,利用大型语言模型(LLMs)作为通用反事实生成器。我们猜测,最新的LLMs具有遵循指令和理解文本的能力,可以高效生成高质量的反事实,无需任何训练或微调。通过广泛的实验验证,我们展示了LLMs作为零样本反事实生成器在评估和解释黑匣子NLP模型方面的有效性。
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何在没有额外训练数据的情况下,利用大型语言模型(LLMs)生成高质量的反事实示例。传统的反事实生成方法依赖于预训练语言模型,并在特定任务的数据集上进行微调,这在实际中不太可行。因此,本研究提出了一个新的问题设置,即零样本反事实生成,并提出了一种结构化方法,利用LLMs作为通用的反事实生成器。
Q: 有哪些相关研究?
A: 相关研究包括反事实生成、自动化反事实生成方法、人类专家注释、大型语言模型(LLMs)、指令遵循和文本理解、模型解释性、模型评估和健壮性测试、模型训练和改进、模型偏见和公平性等。
Q: 论文如何解决这个问题?
A: 论文通过提出FIZLE框架来解决零样本反事实生成问题。该框架利用LLMs作为通用的反事实生成器,无需任何训练或微调,可以生成高质量的反事实示例,用于评估和解释黑匣子NLP模型。FIZLE框架包括利用LLMs生成反事实的结构化方法,通过指令和约束提示来生成高质量的反事实,以及使用评估指标来衡量生成的反事实的质量。
Q: 论文做了哪些实验?
A: 论文通过反事实解释实验和模型评估实验来验证FIZLE框架的有效性。反事实解释实验使用DistilBERT模型作为黑匣子分类器,并利用FIZLE框架的两种变体生成反事实解释。模型评估实验使用不同数据集和任务,在使用FIZLE框架生成的反事实和原始测试集上对目标模型进行评估。实验使用标签翻转得分、语义相似度和编辑距离等指标来衡量生成的反事实解释的质量。
Q: 有什么可以进一步探索的点?
A: 可以进一步探索的点包括改进FIZLE框架、验证生成反事实的忠实度、提高LLM的推理能力、生成反事实的一致性、模型训练和改进、揭示模型偏见、模型公平性、跨领域应用、伦理和偏见问题、混合方法、大规模部署、用户研究等。这些探索点可以帮助研究者更深入地理解和改进LLMs在反事实生成任务中的应用,并推动可解释AI和NLP模型的进一步发展。
Q: 总结一下论文的主要内容
A: 这篇论文的主要内容可以总结如下:
问题定义:论文提出了零样本反事实生成的问题,即在没有额外训练数据的情况下,如何利用大型语言模型(LLMs)生成高质量的反事实示例。
FIZLE框架:作者提出了FIZLE框架,利用LLMs作为通用反事实生成器,无需训练或微调,可生成用于评估和解释黑匣子NLP模型的反事实示例。
实验设计:通过反事实解释实验和模型评估实验,展示了FIZLE框架在解释模型决策和评估模型性能方面的有效性。
评估指标:使用标签翻转得分、语义相似度和编辑距离等指标,衡量生成的反事实的质量。
模型比较:将FIZLE框架与其他反事实生成方法进行比较,展示了FIZLE在不同任务上的性能。
结果分析:实验结果表明,LLMs作为零样本反事实生成器,能够有效生成高质量的反事实,为模型评估和解释提供有力支持。
未来工作:论文探讨了未来工作的方向,包括改进FIZLE框架、验证生成反事实的忠实度、提高LLM的推理能力、探索跨领域应用等。
这篇论文的核心贡献在于提出了零样本反事实生成问题,并提出了FIZLE框架作为通用解决方案。该框架利用LLMs生成高质量的反事实示例,无需额外训练,有助于解释和评估NLP模型。