近年来,人工智能领域取得了令人瞩目的进…
在学习新技术时,一份好的教程可以事半功…
在信息爆炸的时代,获取准确可靠的信息并…
数据可视化是将数据以图表、图形等视觉形…
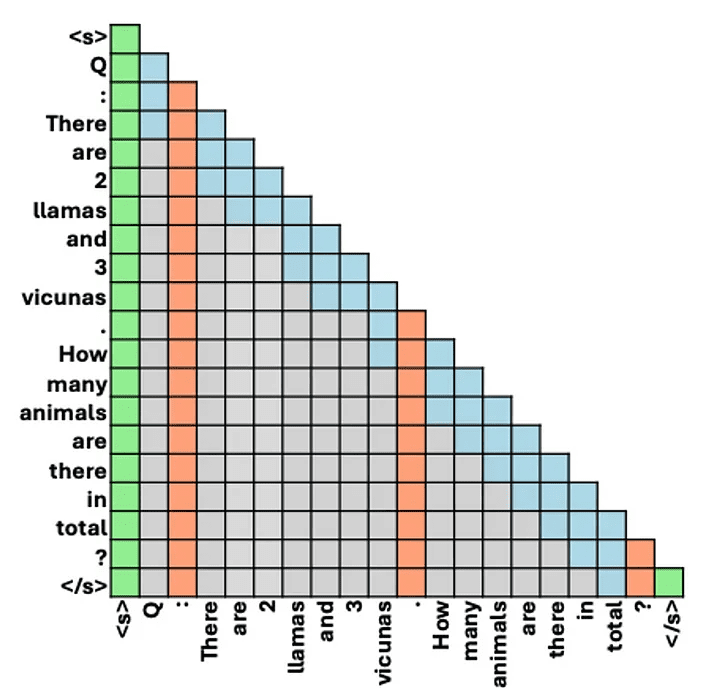
在之前的教程中,我们学习了如何整合开源 …
在之前的教程中,我们学习了如何创建和使…