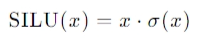在人工智能领域,大模型的快速发展正在深刻地改变着我们的生活。想象一下,未来我们或许可以利用大模型快速扫描整部百科全书、解析复杂的法律条款,甚至精准引用文章内容。然而,现阶段大模型的上下文窗口大小限制了其处理超长文本的能力,阻碍了这些应用场景的实现。
上下文窗口:大模型理解力的瓶颈
大模型的上下文窗口就好比人类的短期记忆,它决定了模型在处理信息时能够参考的范围。传统的预训练大模型通常只有几千个tokens的上下文窗口,例如LLaMA2的最大输入长度为4096个tokens。当输入文本超出这个限制时,模型的性能就会显著下降。
为了解决这个问题,研究人员尝试通过微调技术扩展大模型的上下文窗口。然而,这种方法面临着以下挑战:
- 位置索引的异常值: 扩展上下文窗口会引入大量未经训练的新的token位置索引,导致微调过程难以收敛。
- 长文本数据的缺乏: 微调需要大量的长文本数据,而现有的训练数据集中长文本数量有限。
- 高昂的计算成本: 扩展上下文窗口会导致模型的计算量和内存需求激增,微调过程需要耗费大量的计算资源和时间。
- 注意力分散: 超长上下文窗口会引入过多的位置信息,分散模型的注意力,从而降低其在处理短文本时的性能。
LongRoPE:迈向无限上下文窗口的第一步
为了克服这些挑战,微软亚洲研究院的研究人员提出了LongRoPE技术。LongRoPE首次将预训练大语言模型的上下文窗口扩展到了2048k(约210万)个tokens,并且在保持模型在短文本上性能的同时,显著提升了其处理长文本的效果。
精细化非均匀位置插值:保留关键信息
LongRoPE的核心技术之一是精细化非均匀位置插值。现有的位置插值方法通常采用线性插值的方式,将新的位置索引映射到预训练的范围内。然而,这种方法忽略了RoPE(旋转位置编码)中不同维度和token位置信息的重要性差异。
LongRoPE采用了一种基于进化算法的非均匀插值方法,为RoPE的每个维度和不同的token位置搜索最佳的旋转角度缩放因子。这种方法能够有效地保留原始RoPE位置编码中的关键信息,最大程度地减少了位置插值带来的信息损失。
渐进式扩展策略:高效扩展上下文窗口
在精细化非均匀位置插值的基础上,LongRoPE采用了一种高效的渐进式扩展策略,逐步扩展上下文窗口的大小。
- 首先,在预训练的大模型上搜索256k上下文窗口对应的最佳位置编码插值方案,并进行微调。
- 然后,利用LongRoPE的非均匀插值特性,在不进行微调的情况下将上下文窗口扩展8倍,达到2048k。
恢复短上下文窗口性能:兼顾不同长度文本
扩展上下文窗口后,模型在处理短文本时的性能可能会下降。为了解决这个问题,LongRoPE在扩展后的模型上对8k长度内的RoPE缩放因子进行了重新搜索,以减少短文本上的位置插值程度。在推理过程中,模型会根据输入文本的长度动态调整RoPE缩放因子,从而兼顾不同长度文本的处理效果。
LongRoPE的实验结果
研究人员在LLaMA2-7B和Mistral-7B上对LongRoPE进行了测试,实验结果表明:
- 长文本困惑度降低: 在Proof-pile、PG19和Books3等长文本数据集上,LongRoPE显著降低了模型的困惑度,证明其能够更好地理解长文本信息。
- Passkey检索准确率提升: 在Passkey检索任务中,LongRoPE能够在长文本中准确地检索出隐藏的密码,证明其具备处理超长上下文信息的能力。
- 短文本性能保持: 在Huggingface Open LLM benchmark等标准大语言模型基准测试中,LongRoPE在扩展上下文窗口后,依然保持了与原始模型相当甚至更优的性能。
总结与展望
LongRoPE作为迈向无限上下文窗口的第一步,为大模型的发展带来了新的可能性。未来,我们可以利用LongRoPE构建能够处理超长文本的大模型,例如:
- 阅读和理解整本书籍或长篇文档。
- 分析复杂的法律文件或科学论文。
- 生成更连贯、更具逻辑性的长篇文本。
LongRoPE的出现为大模型的应用开辟了更广阔的空间,让我们共同期待未来更加智能的AI应用。
参考文献
- LongRoPE: Extending LLM context window beyond 2 million tokens. https://arxiv.org/pdf/2402.13753.pdf